


Výpočty na houby můžou být užitečné
Někdy je zajímavé zkusit odpovědět i na otázky, které nedávají smysl. Často se totiž po cestě naučíte něco, co by vás jinak nenapadlo. Tento článek tedy bude úplně nesmyslný, nicméně...

„Tomáš s tatínkem šli na houby. Našli dohromady 18 větších hub. Tomáš řekl, že si je rozdělí do košíků tak, aby měli oba stejně. Tomáš měl ale přesto těžší košík. Jak je to možné?“
(hádanka pochází z pracovního sešitu pro třetí třídy, na Facebooku se o ni loni podělil můj kamarád Jiří Zemánek z ČVUT)

Asi vidíte, že je to tak trochu jiná slovní úloha. Těžko říci, zda úmyslně, nebo omylem. Možná má vybídnout ke kreativitě. A tak jsem si řekl, že ji zkusím “vyřešit”.
Předně je potřeba rozhodnout se, jak budeme chápat vágně položenou otázku “Jak je to možné?” Šlo by třeba spekulovat o tom, že nás vybízí k nějaké úvaze typu
“Tomášův prázdný košík byl těžší než tatínkův prázdný košík” nebo
“mluví se jen o větších houbách, třeba měl více menších hub”.
Pak by ale zadání porušovalo maximu relevance: asi jako ta klasická hádanka “a ten chirurg řekl, že ho nebude operovat, to je můj syn, jak je to možné?”
Předpokládejme nicméně, že slovní úloha s námi hraje férovou hru, dává nám relevantní informace a skutečně se tedy ptá na to, jak je možné, že navzdory snaze rozdělit houby rovnoměrně byl Tomášův koš s houbami těžší.
Následující text je stylově inspirovaný mým oblíbeným autorem a jeho knihou What If: Serious Scientific Answers to Absurd Hypthetical Questions (Randall Munroe).
Co to znamená “těžší”
Je skoro nemožné, aby pouhým rozdělením hub dokázali lidé srovnat hmotnosti tak, aby byly úplně stejné. Stejnou hmotnost, úplně na pikogram stejnou? Je prakticky jisté, že jeden z košíků je těžší, než druhý. Takže proč ne zrovna ten Tomášův, že? To by to ale bylo moc jednoduché.
Těžší bychom měli chápat jako “znatelně těžší”. Pokud by Tomáš ani jeho tatínek nedokázali rozlišit, který z košíků je těžší, nemělo by moc cenu to řešit, z jejich subjektivního pohledu by oba byly stejně těžké a o to při snaze o rozdělení jde.
Překvapilo mne, že výzkum “subjektivního vnímání rozdílů” autorů výzkumu E. Webera a G. Fechnerasahá až do roku 1860, kdy tito němečtí vědci formulovali práh vnímaného rozdílu. Experimentálně zjistili, že se pohybuje kolem pěti procent (přesněji: polovina lidí nepozná rozdíl mezi 100 g a 105 g). Takže “těžší” pro naše potřeby znamená “minimálně o pět procent těžší”. Vida, už se někam dostáváme.
Jak počítat s multivesmírem?
Předpokládejme, že si naši houbaři rozdělují houby do košíků náhodně, tedy každá houba (H1, H2...H18) má stejnou šanci, že se ocitne v košíku K-Tom nebo v košíku K-Táta. Hmotnosti "větších hub" si dáme pro jednoduchost mezi 100 a 300 gramů. (Tady se přiznám, že jsem odhadl opravdu od oka, nenašel jsem narychlo žádný zdroj s hmotnostními statistikami hub)
Teď by mohlo následovat složité počítání kombinací, permutací a pravděpodobností. Pro rychlou představu se mi ale osvědčilo sestavit si rychlou simulaci. Tomuto přístupu se říká “metoda Monte Carlo” a znamená to vlastně řešení problému hrubou výpočetní silou. Vygeneroval jsem v Excelu tisíc scénářů a podíval jsem se, jak dopadly.

Kdybyste si to chtěli vyzkoušet, použil jsem na houby vzorec =INT(RAND()*200+100), který vrací náhodná čísla mezi 100 a 300. Každý řádek má 18 sloupců na houby a poté z těchto sloupců dělám součty (Tomův a tátův koš) a počítám rozdíly těchto součtů.
V takovém případě dojdeme prostou Monte Carlo simulací (1000 scénářů) k následujícímu rozložení: v 29 % případů bude hmotnostní rozdíl obou košíků do 5 %.

Znamená to tedy, že při náhodném rozdělení 18 "větších hub" do dvou prázdných košů (v každém 9 hub) bude v 71 % případů rozdíl v hmotnostech košů postřehnutelný.
Ale pozor. Jak mne záhy Jirka (kterému za toto rozptýlení vděčíme) upozornil, zapomněl jsem na hmotnost košíku. A ta může hrát velkou roli. Chvíli jsem hledal, kolik váží proutěný košík, ale rozptyly byly moc velké. Uděláme to jinak. Zkusíme krajní možnosti. Jak by to vycházelo s lehkým košíkem a jak s těžkým? Tím si totiž zároveň vyzkoušíme, jakou roli hraje hmotnost na košíku při celkovém pohledu.
A vidíme, že hmotnost má opravdu významný vliv. U lehčího košíku se počet simulací, kde byly koše k nerozeznání stejně těžké, zvýšil na třetinu…

…zatímco u ještě těžšího koše už to byla skoro polovina.
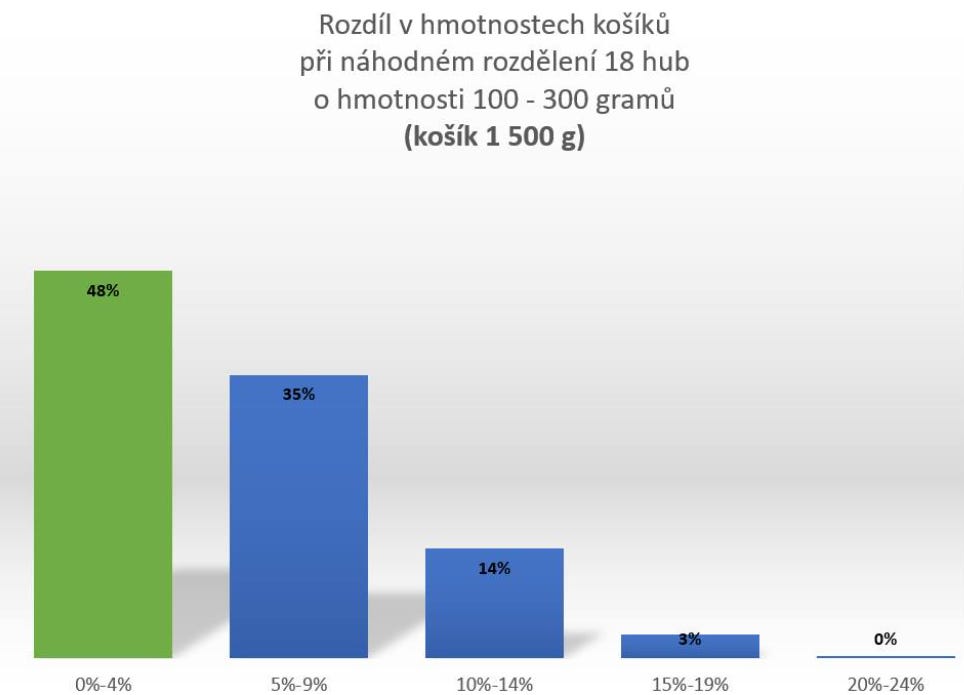
Pořád každopádně platí, že znatelný rozdíl v hmotnosti lze vysvětlit jako celkem běžný a statisticky očekávaný jev. Není třeba za tím hned hledat úmysl. Tedy alespoň pokud se to neopakuje často. Kdyby dostal Tomáš od tatínka těžší koš častěji, pak by měl zbystřit.
Zjednodušme si to a řekněme, že v polovině případů jsou koše k nerozeznání. Tedy zbývá 25 % případů, kdy je znatelně těžší tatínkův koš, a znatelně těžší Tomášův koš. Pokud dostane Tomáš těžší koš poprvé, je to šance 25 %. A správně tušíte, že tu máme variaci na exponenciální křivku, kterou už za poslední rok zná snad každý. Pokud by se to stalo čtyřikrát za sebou, je to 0,25 ^ 4 = 0,00390625, tedy méně než 4 případy z tisíce. To už na důvodné podezření rozhodně stačí.
Šlo by houby rozdělit lépe?
Když už jsme do toho zabředli… Jak by mohli naši houbaři postupovat, pokud by chtěli maximalizovat férovost a minimalizovat případy, kdy je jeden z košů znatelně těžší? Samozřejmě by s sebou mohli nosit váhu a košíky si poměřovat, ale pak by s sebou někdo musel do lesa táhnout těžký přístroj a dostáváme se do úplně nových problémů.
Přitom nepotřebujeme žádné externí přístroje, víme totiž už, že lidé umí porovnat hmotnost dvou objektů s přesností na 5 % hmotnosti porovnávaného objektu. To znamená, že už při rozdělování hub lze výrazně zvýšit pravděpodobnost toho, že výsledné košíky budou mít k sobě hmotnostně blízko.
Jednou z možností je seřadit nalezených 18 hub dle hmotnosti od nejtěžší po nejlehčí. K řazení jen na základě porovnávání dvou hub mohou využít prakticky kterýkoli z algoritmů (tady je pěkná vizualizace, tady podrobnější vysvětlení), u 18 položek to budou mít za chvíli hotové. A pak stačí houby střídavě rozdělit mezi oba košíky…

Teda jejda, pozor, střídavě právě ne! Tím bychom vnesli do jinak náhodných dat informaci, která by ovlivnila výsledek, jeden košík by totiž dostal vždy větší ze dvou za sebou jdoucích položek. Je potřeba rozdělit těch 18 hub na devět dvojic a každou z těch dvojic pak náhodně rozdělit mezi oba košíky. Pak je v 97% všech simulací rozdíl mezi hmotností obou košíků pod 5 %. Našli jsme tedy spolehlivý způsob, jak houby rozdělit férově. Snad to Tomáš ocení.
K čemu jsou takové hádanky?
Přemýšlet nad nesmysly může být velmi užitečné, když to vezmete od podlahy. Všimněte, že jsme začali u divné hádanky s vágním zadáním o čtyřech větách. Pokračovali jsme úvahou o tom, jak vlastně funguje lidské porozumění nejasnému textu. Uvědomili jsme si, že simulace může poskytnout dobrou zkratku k počítání pravděpodobností. Na konci máme tabulku s tisíci řádky a vyzkoušeli jsme si matematickou intuici i její praktické ověření na datech (byť se jedná o měkké, náhodné a nadto imaginární houby).
Já tuhle hádanku zařadil do svého školení “základy statistiky v Excelu” a musím říct, že mi počítání něčeho, co nekončí na jednotkách intenzivní péče, příjemně pročistilo hlavu. Tak snad vás to bavilo taky. Zamýšlet se nad nesmysly totiž může dávat smysl, když to uděláte pořádně.
Mimochodem, nabízím jiné řešení původní úlohy. Domnívám se, že jde o řešení, které měl zadavatel úlohy na mysli.
Vyskytují se v ní dvě klíčová slova, která poněkud podvědomě zaměňujeme, jenže často je to chyba. Jde o slova "větší" a "těžší". Je známo, že houby jsou dobře nasákavé vodou. Proto oba mohli mít po párech úplně stejně velké houby a stejný počet, avšak Tomáš měl ty s větším obsahem vody. Dokonce mu je tatík mohl takto vybírat, aby mu udělal radost, že jich má podle hmotnosti více.
Přesně tyto myšlenkové postupy jsou základem vědeckých postupů a mnohých vědeckých prací. Matematické postupy jsou spolehlivé, ale vyžadují přesně formulovaný problém k řešení. A právě přeformulovat a zjednodušit do té správné míry daný problém, aby byl logicky řešitelný, a přitom ho nezjednodušit příliš, aby řešení bylo přínosné našemu poznání, je snad to nejtěžší.
Vámi zvolený příklad je docela pěkný.
A ještě konkrétní příspěvek. Zvolil jste sice náhodné rozložení hmotnosti hub, navíc v nedostatečně dobře zdůvodněných mezích 100-300 g, ale hodně nereálné rozložení, tedy tzv. rovnoměrné. Mnohem reálnější je rozložení zvané "normální" nebo-li Gaussovo. Zkuste změnit ve vaší simulaci tu generující funkci na normální rozložení (nejspíš to ve vámi použitém jazyku bude znamenat nahradit funkci rand funkcí randn a změnit koeficient a aditivní konstantu) a porovnat výsledek, který vás zajímá.